Fluentd
A detailed guide for designing the setup of Fluentd architecture
Fluentd is an open source data collector, which lets you unify the data collection and consumption for a better use and understanding of data. Fluentd tries to structure data as JSON as much as possible: this allows Fluentd to unify all facets of processing log data: collecting, filtering, buffering, and outputting logs across multiple sources and destinations.

Features
- JSON Logging: Fluentd tries to structure data as JSON as much as possible: this allows Fluentd to unify all facets of processing log data: collecting, filtering, buffering, and outputting logs across multiple sources and destinations.
- Pluggable Architecture: Fluentd has a flexible plugin system that allows the community to extend its functionality. Our 500+ community-contributed plugins connect dozens of data sources and data outputs.
- Minimum Resources Required: Fluentd is written in a combination of C language and Ruby, and requires very little system resource. The vanilla instance runs on 30-40MB of memory and can process 13,000 events/second/core.
- Built-in Reliability: Fluentd supports memory- and file-based buffering to prevent inter-node data loss. Fluentd also supports robust failover and can be set up for high availability.
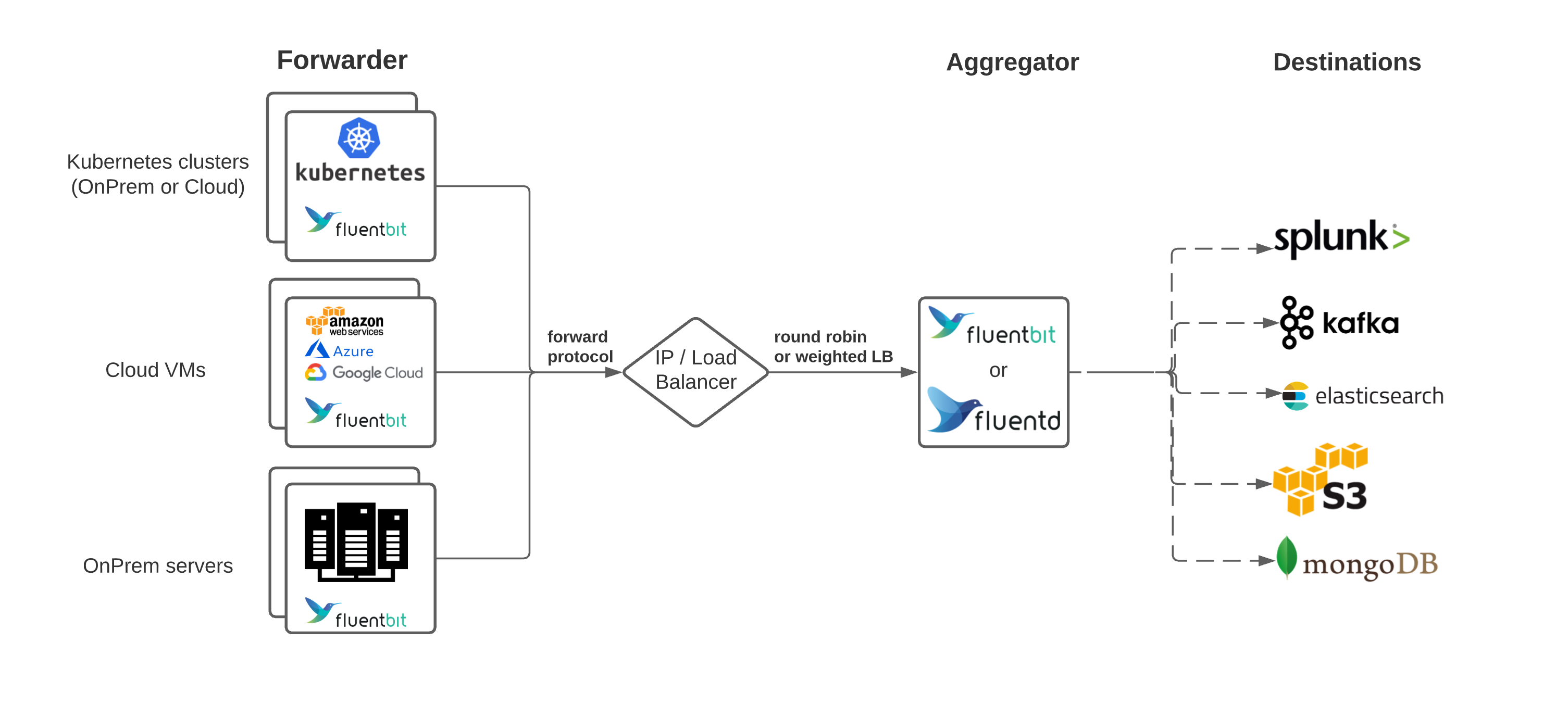
Architecture
Last modified June 6, 2022: [Documentation][Add] Added initial documentation (#35) (2c331c4)