Logging Operator is an operator created in Golang to set up and manage EFK(Elasticsearch, Fluentd, and Kibana) cluster inside Kubernetes and Openshift environment. This operator is capable of setting up each individual component of EFK cluster separately.
Architecture
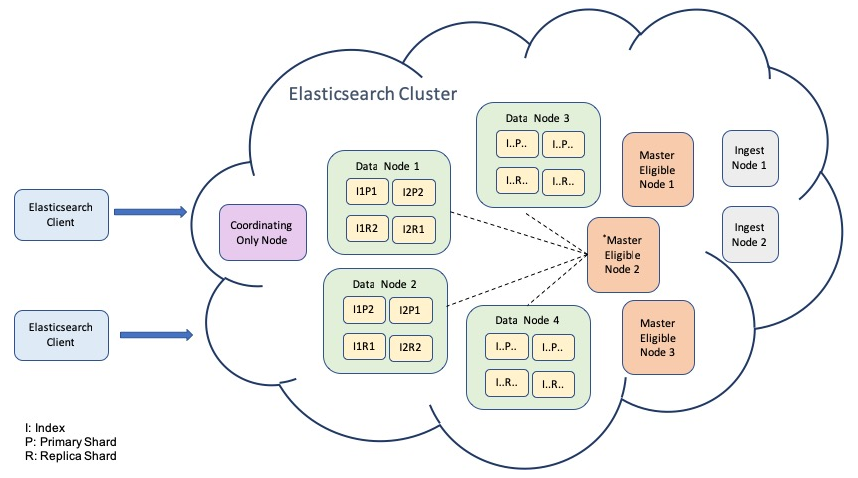
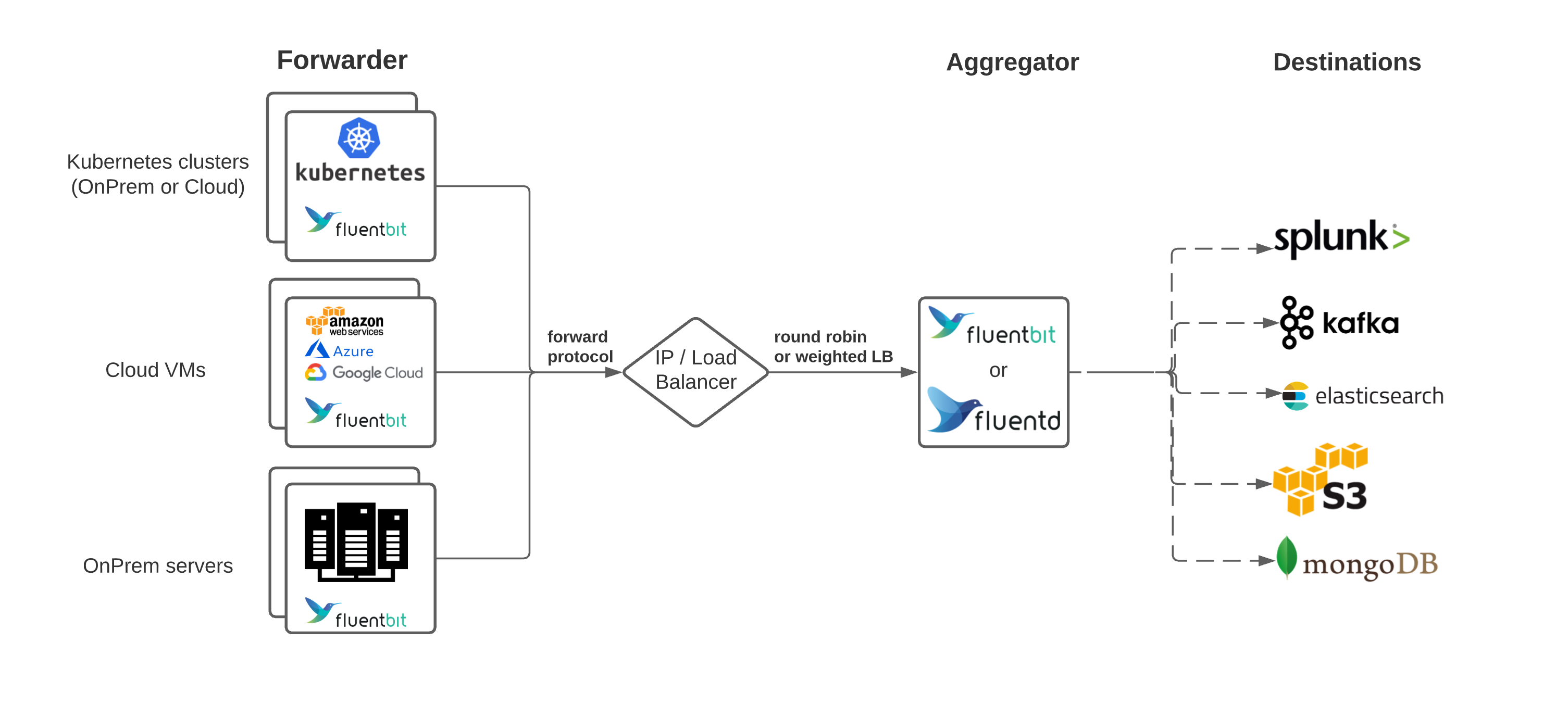
Architecture for Logging operator looks like this:-

Purpose
The aim and purpose of creating this Logging Operator to provide an easy and extensible interface to setting up logging stack such as EFK(Elasticsearch, Fluentd, and Kibana). It helps in setting up different nodes of elasticsearch cluster, fluentd as a log shipper and kibana for visualization.
Supported Features
- Setup of elasticsearch cluster with different nodes type:- master, data, ingestion, and client.
- Customizable configuration for elasticsearch, fluentd stack.
- Setup of fluentd as light-weight log-shipper as Daemonset.
- Kibana will be set up as visualization tool for elastic stack.
- Seamless upgrades of elasticsearch, fluentd, and kibana.
- Security best practices support for complete stack such as TLS, elastic security.
- Kubernetes resources objects support like:- resources, securityContext, affinity, tolerations, etc.